
Роль фазовых соотношений сигналов в звукозаписи
Автор: Александр Михлин
Фазовые отношения сигналов – одна из самых интересных, неизведанных, даже таинственных областей в современной звукозаписи. Это область, которая для звукорежиссера часто связана с интуицией и везением, область, трудно поддающаяся достоверным прогнозам, требующая расчетов, не всегда оперативно доступных в студийной ситуации. Если в отношении баланса, тембров, планов звучания, пространственности записи мы обычно в какой-то степени контролируем ситуацию, то при решении проблем, возникающих с фазовыми соотношениями сигналов, бывает непонятно, что послужило причиной возникновения проблемы и что конкретно нужно сделать, чтобы ее преодолеть.
Итак, фазовые проблемы могут возникнуть при сложении двух или более сигналов в звуковом тракте (то есть, по сути, при любом микшировании). При этом происходит суммирование напряжений, и если сигналы различаются по своему частотному составу, то образуется новый сигнал, включающий в себя компоненты обоих исходных сигналов. Если же сигналы близки/идентичны по составу или имеют совпадающие частотные компоненты, то важную роль начинает играть фазовое соотношение этих компонентов.
Под хорошей фазовой совместимостью будем понимать свойство сигналов иметь минимальное число противофазных составляющих и при сложении максимально сохранять исходные тембральные характеристики. Плохая фазовая совместимость может пагубно сказаться на качестве звучания и привести к неприятным последствиям.
Один из частных случаев – сложение в моно стереофонограммы. Несмотря на то что сейчас уже практически повсеместно распространены стереосистемы воспроизведения звука, моно все же встречается в нашей жизни. Яркий пример – телевидение: большинство российских телеканалов все еще вещают в моно. А значит, если на ТВ попадет фонограмма, плохо совместимая в моно (имеющая много противофазных составляющих), то прозвучать она может совсем не так, как в стереоварианте. Могут произойти серьезные тембровые изменения – про- пасть определенные полосы частот; может измениться баланс. Если фонограмма совсем плохо совместима в моно, может упасть общий уровень.
Фазовые соотношения сигналов при многомикрофонной акустической записи
Итак, фазовые аспекты в звукорежиссуре очень важны. Поэтому речь более подробно пойдет о процессах взаимодействия фаз сигналов двух и более микрофонов, используемых одновременно при многомикрофонной записи, а также об управлении этими процессами.
Рассмотрим распространенную ситуацию за- писи акустической музыки. Руководствуясь принципами трехплановой звукорежиссуры (имеется в виду постановка трех различных пар микрофонов – дальней, главной и ближней), звукорежиссер при записи обычно использует дальние микрофоны, которые должны помочь при создании пространственного решения записи, главные микрофоны, цель которых – максимально правильно отобразить звуковую «картинку», и индивидуальные микрофоны, призванные улучшить тембральные характеристики звучания или помочь в исправлении недостатков баланса.
В описанной ситуации все исполнители находятся в одном помещении и играют одновременно, поэтому сигнал одного и того же инструмента попадает на разные микрофоны. Так как микрофоны выставлены на расстоянии друг от друга, сигнал попадает на них не одновременно, со сдвигом по времени. Таким образом, сигнал одного и того же источника оказывается на разных микрофонах в разной фазе. И затем, при микшировании, происходит сложение сигналов, что создает ситуацию, описанную выше, – суммирование похожих сигналов с разной фазовой характеристикой.
Один из главных результатов сложения похожих или идентичных сигналов с задержкой по времени – так называемая гребенчатая фильтрация (англ. comb filtering). Это словосочетание ассоциируется у нас со своеобразным рисунком, возникающим на анализа- торе спектра при сложении прямого и задержанного сигналов (рис.1). Картинка действительно напоминает гребенку («comb» – гребенка (англ.)). Гребенчатая фильтрация – это, по определению, «возникновение периодических глубоких провалов или пиков в частотной характеристике, обычно вызванное сложением прямого сигнала и отраженного, приходящего с небольшой задержкой».
На рисунке показаны три амплитудно-частотные характеристики. Верхняя из них – характеристика некоего исходного сигнала. Нижние характеристики – результат сложения исходного сигнала со своей же копией, задержанной на 1,4 мс. Оба графи- ка как раз отражают описанное выше – периодические пики и провалы АЧХ. Разница между ними – в уровне подмешиваемого сигнала: в одном случае он составил -10 дБ, в другом – -20дБ.
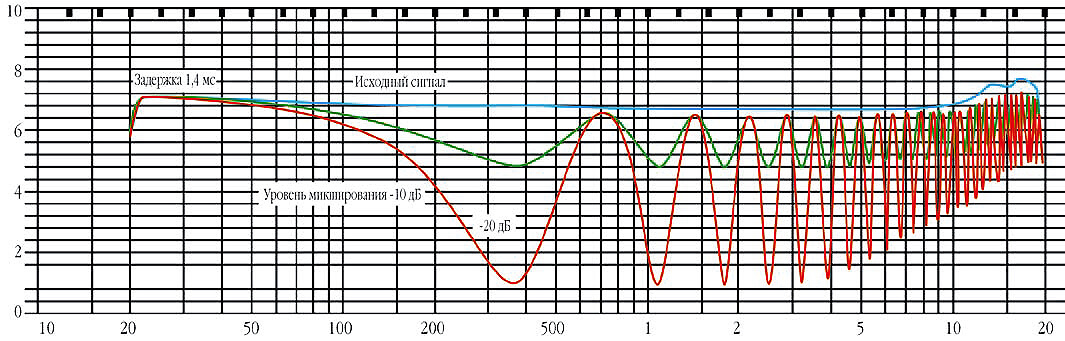
На практике гребенчатая фильтрация может быть вызвана также сложением полезного сигнала с его же задержанной копией – например, когда складывается «сумма» микшерного пульта с сигналом, возвращенным с записывающего устройства. При этом возникает характерное изменение тембра, которое опытные звукорежиссеры тут же идентифицируют на слух. Нечто подобное, менее явное и в меньших объемах, происходит и в описываемой ситуации многомикрофонной записи, когда один и тот же сигнал приходит с задержкой на разные микрофоны и затем суммируется. Результат этого обычно не так фатален, как в предыдущей ситуации, но все же могут быть привнесены явно слышимые искажения и ухудшения звука.
Эффект Хааса
Кроме гребенчатой фильтрации в нашем контексте следует упомянуть эффект Хааса (или эффект предшествования).
Это важная особенность бинаурального слуха. Суть заключается в том, что в пределах определенного отрезка времени звуковой сигнал, поступивший ранее, доминирует над сигналом, поступившим позднее. Эффект Хааса очень ясно объясняется на примере с двумя акустическими системами. Если подать на них одинаковый сигнал без задержек, слушатель, соответственно бинауральному эффекту, локализует источник звука посередине между громкоговорителями. При добавлении задержки к одному из каналов слуховой образ начинает смещаться в сторону другого и, когда задержка достигает 10 мс, полностью совпадает с другим громкоговорителем. Далее, при увеличении задержки вплоть до 50 мс, звук будет казаться приходящим только с одной стороны. При этом вторая акустическая система работает, ее сигнал воспринимается слуховой системой, но как бы подавляется мозгом. Между тем этот сигнал все-таки создает некое ощущение объема. При дальнейшем увеличении задержки (более 50 мс) сигнал второй акустической системы становится слышим как эхо.
Как же связан эффект Хааса с компенсацией задержки сигнала?
Чтобы понять это, кратко напомним об особенностях распространения звука в помещениях. Представим себе концертный зал, в котором на сцене находится источник звука (например, музыкальный инструмент), и слушателя, сидящего в этом зале на некотором удалении от сцены. Какой сигнал и в какой последовательности воспринимает слушатель? (рис. 2).
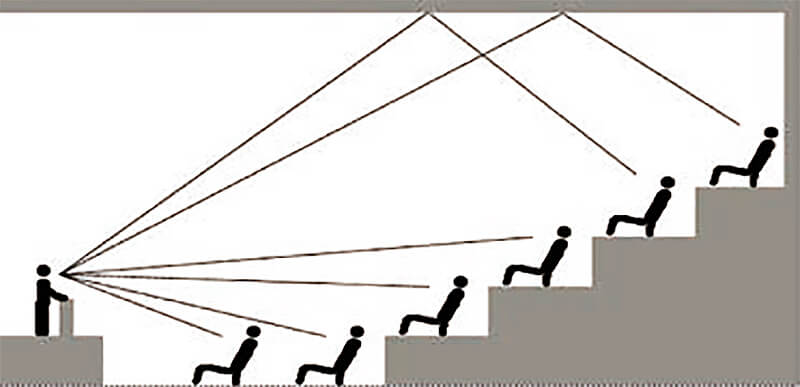
Вначале он слышит прямой сигнал, приходящий от инструмента по кратчайшему пути. Этот сигнал ясно воспринимается слушателем как первый пришедший сигнал.
Далее начинают приходить так называемые ранние отражения – первые дискретные отражения звука от потолка, пола, боковых стен, других поверхностей. Чаще всего мы не идентифицируем отчетливо первые отражения. За счет эффекта Хааса они воспринимаются вместе с прямым сигналом, но все же дают слуху важную информацию о помещении – о его архитектурных и акустических характеристиках – размерах, глубине, ширине. Поэтому первые отражения так важны – не зря набор параметров early reflections присутствует почти в любом профессиональном ревербераторе. Удачная имитация первых отражений уже во многом дает представление о помещении.
Вслед за стадией ранних отражений следует период равномерного, постепенно затухающего диффузного отзвука. Это собственно тот реверберационный отзвук помещения, который мы ясно воспринимаем и можем отдельно идентифицировать. По нему мы оцениваем степень гулкости зала; по тембру отзвука мы судим о «красоте акустики».
Итак, что происходит, когда в записи смешиваются сигналы, например, ближнего и главного микрофонов? Слушатель в зале сначала воспринимает прямой сигнал, обогащенный первыми отражениями. Но в записи, особенно если уровень сигнала ближнего микрофона велик, первым становится слышен сухой сигнал ближнего микрофона, который почти не обогащен первыми отражениями, так как стоит близко к инструменту. Только потом с задержкой от главного микрофона приходит правильное сочетание прямого звука и следующих затем ранних отражений, которое должно давать наиболее естественную «картинку».
Такая последовательность находится в несоответствии с привычной слуху реальностью – нарушаются естественные порядок и время прихода сигнала: прямой звук с ближнего микрофона приходит раньше времени, отделяясь от остального звука. При этом ранние отражения теряют тем самым естественное «обогащающее» временное соотношение с прямым звуком, так как для этого должны были бы прийти раньше – сразу после прямого звука с индивидуального микрофона.
Кроме того, есть основания полагать, что здесь играет роль и уже упомянутый эффект Хааса. Если доля индивидуального микрофона в миксе довольно высока, то приходящий с него сигнал может частично маскировать сигнал общего микрофона, приходящий с задержкой. И если это так, информация о ранних отражениях может частично замаскироваться, что ухудшит естественное восприятие пространства.
Конечно, тут сразу действует несколько механизмов маскировки, в том числе и маскировка по балансу, и тембральная маскировка. Но описанное проявление эффекта Хааса все же тоже может сыграть свою роль.
Как проявляются описанные особенности многомикрофонной записи в звучании? Про последствия гребенчатой фильтрации здесь уже говорилось – это искажения тембра; также из-за маскировки ранних отражений может утратиться ощущение пространства, глубины зала и ширины звуковой картины.
Исторический обзор работ по теме
Очевидно, что прямолинейное использование многомикрофонной техники при записи акустической музыки может оказать нежелательное влияние на качество звучания. Имеется ряд работ зарубежных звукорежиссеров и ученых-акустиков по этой проблематике. Вот краткое изложение наиболее интересных публикаций.
Доклад швейцарского звукорежиссера Йорга Йеклина, который был представлен на 65-й конвенции AES в Лондоне (1980), назывался «Другой способ записи классической музыки» и главная его тема – презентация известной сейчас микрофонной стереосистемы «Диск Йеклина», которая в этом докладе называется OSS-микрофон (Optimal Stereo Signal). Доклад содержит подробное описание всех свойств и характеристик этой системы и даже чертежи, по которым можно собственноручно изготовить сам диск, поэтому работой можно пользоваться как инструкцией от автора по изготовлению и применению системы.
Во вступительной части доклада Йеклин сетует на то, что хотя техника записи поп-музыки (имеется в виду многомикрофонность) и начала проникать в сферу академической музыки, но, тем не менее, новые записи не звучат лучше старых. Поэтому, при наличии хороших исполнителей, играющих в подходящих акустических условиях, автор не видит смысла использовать много микрофонов и советует ограничиться одним стереомикрофоном либо стереопарой. Любопытно, что Йеклин делит всю музыку на две категории, называя одну «микрофонная» (то есть изначально музыкально и акустически несбалансированная – подразумевая поп-музыку), а другую – «натуральная» (напротив, сбалансированная во всех отношениях, теоретически пригодная, при благоприятных условиях, для записи точечным микрофоном one-point).
И далее, говоря о варианте добавления к основному микрофону индивидуальных, он тут же замечает, что для индивидуальных микрофонов обязательно должна быть введена задержка, исходя из расстояний до главного микрофона.
Далее, описывая возможность добавления индивидуального микрофона при использовании новой технологии (запись на OSS-микрофон), автор отмечает, что ближние микрофоны разрушают важные фазово-временные соотношения между стереопарой в системе «диск Йеклина» и поэтому также должны быть обязательно задержаны по времени в соответствии с расстояниями. Тогда, тщательно панорамируя индивидуальные микрофоны в соответствии с панорамой соответствующих инструментов на главной паре, можно усилить сигналы с этих микрофонов в миксе. Пространственное впечатление и естественные временные соотношения при этом не пострадают, но рельефность тембра станет ярче и план – чуть ближе.
Примечательно, что Йеклин уже в 1980 году говорил о компенсации задержки при записи, как об операции, само собой разумеющейся. Это показывает, что данная технология записи не является неким умозрительным плодом сложных научных исследований, а естественным образом вытекает из простых законов физики, и, судя по всему, оказывает значительное влияние на качество записей.
Еще одна работа, которую стоит упомянуть, – это совместный доклад японских звукорежиссеров Т. Аназава и Ю. Такахаши и американского инженера и звукорежиссера Э. Клегга, представленный на 83-й конвенции AES в Нью-Йорке в 1987 году. Доклад называется «Техника фазово-совместимой цифровой записи». Авторы отмечают эффект гребенчатой фильтрации, возникающий при многомикрофонной записи, и приводят результаты экспериментов по определению границ восприятия слушателями этого эффекта. В ходе эксперимента брался некий звук и подмешивался к своей же копии. При этом изменялась степень подмешивания и величина задержки подмешиваемого звука. Слушателям предлагалось отмечать момент, когда гребенчатая фильтрация становилась слышна. Уровень подмешиваемого звука в этот момент и отмечался как порог детектирования.
Выяснилось, что такого рода искажения становятся слышны уже при довольно низком уровне подмешивания.
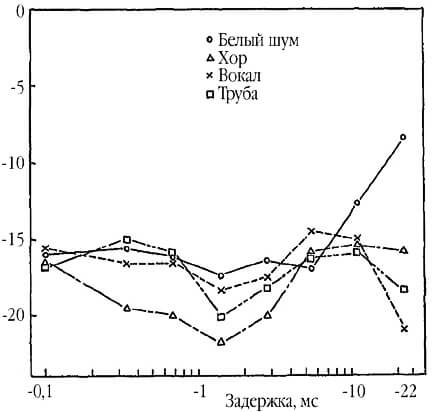
На графике (рис 3) по горизонтали отложена вели- чина задержки, по вертикали – уровень подмешиваемого звука. Чем ниже опускается график, тем «раньше» эксперт при прослушивании отмечал заметность гребенчатой фильтрации. Как видно из графика, этот порог зависит от источника звука. Эксперименты проводились на примере хора, вокала, трубы и белого шума. Наиболее подвержен таким искажениям оказался хор – как видно из графика, на определенных величинах задержки искажения становились слышны уже при уровне подмешивания менее -20 дБ!
Также из этого графика можно сделать вывод, какая длина задержки вызывает наиболее явно воспринимаемые на слух искажения – судя по графикам, это задержки менее 1,5 мс, а также от 3 до 10 мс, что соответствует расстояниям между микрофонами от 0 до 34 см и от 1 до 3,5 м.
Тут, конечно, стоит отметить, что в реальной ситуации пороги заметности могут быть выше – даже если взять только прямой сигнал, то он приходит неодинаковым на ближние и главные микрофоны, и поэтому возникающая гребенчатая фильтрация может быть не столь явной. Однако этот эксперимент все же дает интересную, полезную и важную информацию.
На основании результатов своих исследований авторы доклада сделали два важных заключения:
• ухудшение качества звучания происходит даже в том случае, если уровень ближнего микрофона всего на 10 дБ ниже уровня главного;
• в зависимости от музыкального инструмента ухудшение может произойти даже при задержке всего лишь 300 мс (около 10 см от источника), поэтому желательно соблюдать точность измерения задержки до 1 мс или даже еще точнее.
Еще одна интересная работа по теме – это доклад американского звукорежиссера Терезы Леонард на 95-й конвенции AES в Нью-Йорке в 1993 году. Работа называется «Компенсация задержек сигналов микрофонов при записи: экспериментальная оценка».
Прежде всего следует отметить идею, которую Тереза Леонард излагает со ссылкой на немецкого инженера Гюнтера Тайле. В одной из своих работ Тайле, помимо безусловной рекомендации использовать компенсацию при записи, советует к вычисленной в соответствии с расстояниями задержке добавлять еще немного дополнительной задержки, чтобы прямой сигнал с индивидуального микрофона оказывался звучащим вместе с первыми ранними отражениями на общем микрофоне.
Основная часть доклада – это описание процесса и представление результатов большой исследовательской работы, проведенной Терезой Леонард. Группе слушателей-экспертов из числа профессиональных звукорежиссеров был предложен ряд академических записей симфонической и камерной музыки. Записи были выполнены с использованием многомикрофонной техники и представлены слушателям в разных вариантах, как традиционных, без компенсации задержек, так и с разным временем компенсации: с вычисленным временем, с чуть большим и чуть меньшим, чем вычисленное (по Тайле). Естественно, слушателям не сообщалось, где какая запись.
Целью эксперимента было понять из комментариев слушателей:
• как воспринимаются маленькие задержки – через небольшие изменения баланса, глубины, тембра, громкости или другое;
• преодолевает ли компенсация задержки эффект гребенчатой фильтрации и улучшает ли ощущение глубины;
• существует ли оптимальная задержка;
• улучшает ли данная технология баланс записи.
Результаты исследования показали, что компенсация задержки не только заметна на слух, но и усиливает восприятие глубины оркестра. В большинстве случаев варианты с компенсацией задержки были для слушателей предпочтительней, чем без нее. В отношении времени задержки результаты варьировались: где-то большинством была выбрана точно вычисленная задержка, где-то чуть большая, реже – чуть меньшая. Часто отмечалось, что применение задержки на индивидуальный (ближний) микрофон благотворно сказывается на звучании этого инструмента, но плохо влияет на общий баланс. Отмечалось, что разница в несколько миллисекунд задержки имеет эффект, схожий с фокусировкой камеры – в какой-то момент звук инструмента или группы «попадает в фокус» и звучит хорошо в общем балансе. Также отмечалось изменение баланса инструментов в результате компенсации и, соответственно, необходимость коррекции уровня того или иного микрофона.
В конце Т. Леонард отмечает, что компенсация задержек – это все-таки не универсальный рецепт для любой ситуации, а в некоторых случаях не исключено даже противоположное применение задержки – задержка общих микрофонов с целью сделать акцент на индивидуальных – в качестве особого эффекта.
(Продолжение следует…)