MP3 – «вечно живой»? Разговор c Алексеем Лукиным о компрессии «с потерями»
Автор: Анатолий Вейценфельд
Кажется даже забавным, что такая сугубо техническая разработка, как формат цифрового аудиофайла, смог стать еще и культурным феноменом. Или даже этапом в развитии культуры, прежде всего музыкальной. Однако так и есть – появление в свое время формата МР3 оказало на всю музыкальную индустрию влияние, подлинный масштаб которого нам еще предстоит осмыслить. Превосходит его по значимости разве только создание цифровой звуковой технологии как таковой. Ведь именно МР3 позволил массово распространять фонограммы с достаточным качеством в цифровых сетях с умеренным потоком, хранить огромные архивы звукозаписей на сравнительно небольших по объему носителях информации, организовать цифровое музыкальное вещание и т.д. и т.п.
При этом какие только негативные слова не высказывались по отношению к МР3 и профессионалами, и потребителями на протяжении тех лет, когда он был в активном пользовании по всему миру! Были ли эти слова справедливы? Много ли мифов вокруг МР3? Каковы его достоинства и недостатки по сравнению со вторым по популярности форматом ААС?
Об этом мы беседуем с одним из крупнейших международных специалистов по цифровым аудиотехнологиям, лауреатом награды американской киноакадемии Алексеем Лукиным, хорошо и давно знакомым нашим читателям. Перед началом беседы небольшая ремарка. Много лет назад я беседовал с некоторыми из создателей формата МР3 из Фраунгоферовского института в Германии. Один из них сказал важную вещь: МР3 в 1995, 2003 и 2013 годах – это, по сути, разные технологии. Алгоритмы психоакустической компрессии все эти годы постоянно изучались и совершенствовались, разработчики не стояли на месте, так что МР3 в начале и через 15 лет – это совсем разные записи, разное звучание. И это важно иметь в виду, говоря о формате.
— Алексей, «ты помнишь, как все начиналось»?
— Лично я не все помню, конечно, не такой старый еще (смеется). Ведь первые идеи об использовании психоакустической маскировки для компрессии аудиоданных относятся к 1979 году. А первые аудиокодеры начали получать широкое распространение лишь с середины 1990-х годов, когда вычислительных мощностей персональных компьютеров стало хватать для воспроизведения сжатого аудио в реальном времени. Тогда и появился стандарт MPEG-1 Audio Layer 3, более известный как МР3. Аудиоформаты с компрессией стали незаменимыми при передаче звука через интернет, обеспечивая «практически прозрачное» качество стереозвука при битрейтах выше 128 кбит/с.
— Интересная формулировка – «практически прозрачное». Что это значит?
Прозрачный – то есть не содержащий примесей, артефактов. Это значит, что большинство слушателей не может отличить кодированный сигнал от оригинала.
Развитие методов сжатия данных и психоакустики постепенно привело к тому, что стандарт МР3 стал «тесным» для реализации новых идей в кодировании аудио. В результате в конце 1990-х создатель МР3 институт Фраунгофера (Fraunhofer IIS), а также компании Dolby, AT&T, Sony и Nokia разработали новый метод компрессии аудио – Advanced Audio Coding (AAC), вошедший в стандарты MPEG-2 и MPEG-4. Основными отличиями от стандарта МР3 стали:
– поддержка более широкого набора форматов (вплоть до 48 каналов) и частот дискретизации звука (от 8 кГц до 96 кГц);
– более эффективный и простой банк фильтров: гибридный банк фильтров МР3 был заменен обычным MDCT (модифицированным дискретным косинусным преобразованием);
– более широкие пределы варьирования частотно-временного разрешения в банке фильтров – в восемь раз (в МР3 – в три раза), что привело к улучшению кодирования транзиентов (переходных процессов) и стационарных участков аудиосигнала;
– более качественное кодирование частот выше 16 кГц;
– более гибкий режим кодирования стереосигналов, позволяющий переключаться в режим M/S (“joint stereo”) независимо в различных частотных полосах.
Появились и дополнительные возможности стандарта, повышающие эффективность компрессии: технология формирования шума во временной области (TNS), предсказание MDCT-коэффициентов по времени (long-term prediction), режим параметрического кодирования стереосигнала (parametric stereo), синтез шумов (perceptual noise substitution), технология восстановления верхних частот (SBR).
Благодаря этим особенностям стандарт AAC способен достигать более гибкого и эффективного, а значит – и более качественного кодирования звука. В последние годы популярность AAC уже превысила MP3, в значительной степени – благодаря стриминговым платформам.
— Самое время рассмотреть основные особенности AAC подробнее…
Как и другие психоакустические аудиокодеры, AAC работает по следующей схеме. Входной сигнал пропускается через банк фильтров – преобразование, переводящее сигнал из временной области в частотно-временную область (аналогично построению спектрограммы). Параллельно с этим психоакустическая модель анализирует сигнал и определяет пороги психоакустической маскировки. Далее спектральные коэффициенты сигнала на выходе банка фильтров квантуются так, чтобы спектр шума по возможности (если позволяет битрейт) оказался ниже порогов маскировки и не был слышен. Квантованные коэффициенты сжимаются без потерь в выходной файл формата AAC. Таким образом, сам банк фильтров не сжимает сигнал, он лишь переводит его в форму, более пригодную для сжатия. 72
Особенностью каждого банка фильтров является его частотное разрешение, то есть число частотных полос, на которые он делит спектр сигнала. В большинстве банков фильтров, используемых для сжатия звука, число полос составляет несколько сотен. Такие банки фильтров имеют временное разрешение порядка нескольких десятков миллисекунд.
— Как это сказывается на качестве звука?
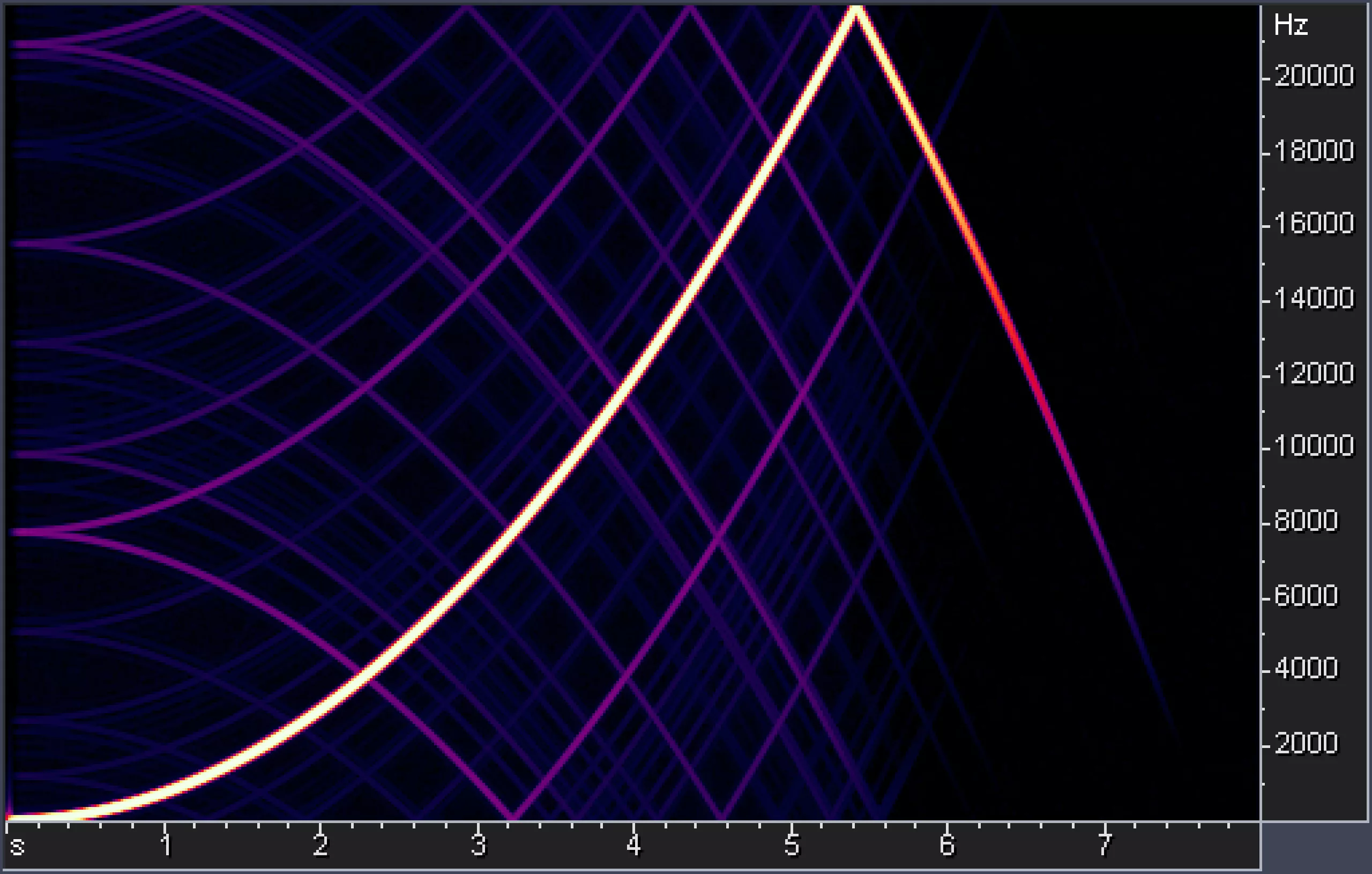
Когда спектральные коэффициенты сигнала квантуются, то вносимая ошибка квантования (надеюсь, всем знакомо это базовое понятие цифрового звука?) при декодировании сигнала распространяется по времени на всю длину окна банка фильтров. В некоторых случаях это приводит к нежелательному эффекту, называемому пред-эхом (pre-echo). Он проявляется, когда ошибка квантования, возникшая из-за транзиентного импульса, то есть резкого всплеска энергии в сигнале, распространяется по времени на предшествующий транзиенту участок времени и становится слышна (рис. 1).
-Да, это известный и заметный артефакт. Можно ли с этим бороться?
Чтобы уменьшить этот эффект, применяют банки фильтров с переменным частотно-временным разрешением. Например, в МР3 используется переключение временного разрешения банка фильтров между 26 и 9 мс. Для стационарных (медленно меняющихся, тональных) сигналов используются окна длиной 26 мс, дающие хорошее частотное разрешение, а для транзиентов используются окна длиной 9 мс, уменьшающие эффект предэха (см. рис. 1).
В алгоритме AAC также используется переключение размера окон MDCT. При этом разница в размере окон восьмикратная: 6 и 48 мс (256 и 2048 отсчетов). Благодаря этому алгоритм способен адаптироваться к более широкому диапазону сигналов и достигать лучшей степени компрессии.
— Что можно рассказать про технологию TNS, которая была впервые использована в ААС?
Одной из проблем современных психоакустических кодеров аудиосигнала является работа с транзиентами (переходными процессами в аудиосигнале). Для обеспечения прозрачного кодирования нужно обеспечить, чтобы шум квантования был ниже порога маскировки, зависящего от времени. Однако на практике этому требованию трудно удовлетворить вблизи переходных процессов, т.к. шум квантования при декодировании распространяется по времени на всю длину окна MDCT. Это может приводить к значительным превышениям шумом квантования порогов временной маскировки.
Технология TNS (temporal noise shaping, формирование шума во временной области) в стандарте AAC позволяет управлять распространением шума квантования по времени в пределах каждого окна MDCT. Технология TNS основана на подобии амплитудной и спектральной огибающих сигнала (это называется «частотно-временной дуализм»), а также на использовании линейного предсказания (LPC) по частоте при квантовании спектра.
— Тут, наверно, нужно пояснить насчет этого «предсказания»?
Хорошо известно, что для сигналов со спектром, сильно отличающимся от белого (например, обычных тональных сигналов), использование линейного предсказания (LPC) во временной области позволяет эффективно «отбеливать» спектр и кодировать такие сигналы путем их разложения на коэффициенты предсказания и сравнительно небольшую по амплитуде ошибку предсказания. Тогда при декодировании фильтр линейного предсказания формирует спектр ошибки согласно спектру исходного сигнала.
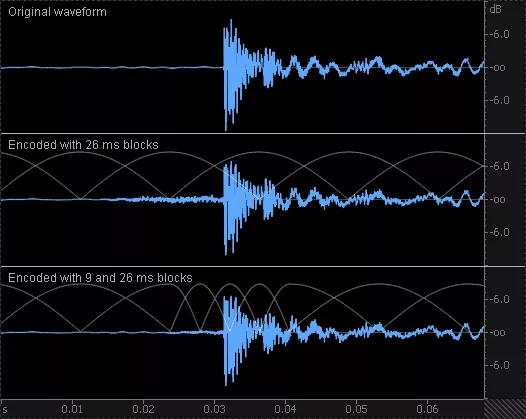
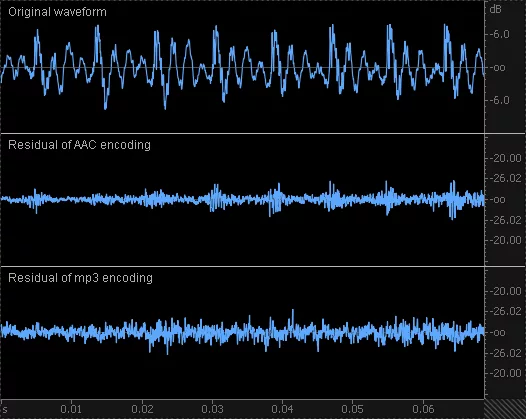
А вот в кодере AAC линейное предсказание используется противоположным образом: для предсказания отсчетов спектра в частотной области. Разность исходных и предсказанных коэффициентов MDCT квантуется согласно порогам маскировки. (Тут надо отметить, что в традиционных кодерах квантуются исходные коэффициенты MDCT). Коэффициенты линейного предсказания также записываются в выходной файл. При декодировании сигнала фильтр линейного предсказания, применяемый к разностному сигналу в частотной области (включающему ошибку квантования), формирует амплитудную огибающую исходного сигнала (и ошибки квантования) во временной области. Таким образом, амплитудная огибающая ошибок квантования становится близкой к амплитудной огибающей исходного сигнала (рис. 2).
— «Огибающая ошибок квантования становится близкой к огибающей сигнала» – это достижение?
Да, поскольку технология TNS снижает эффект пред-эха и заметность ошибок квантования на некоторых гармонических сигналах с импульсным характером звукоизвлечения (речь про некоторые духовые и струнные смычковые инструменты). На рис. 2 сравниваются ошибки квантования, вносимые в вокальный сигнал алгоритмами AAC и МР3 с одинаковыми битрейтами. Вместе с общим понижением ошибки квантования (в силу большей эффективности AAC) наблюдается формирование амплитудной огибающей ошибки квантования по времени согласно огибающей исходного сигнала.
В стандарте AAC технология TNS может применяться независимо к отдельным частотным полосам спектра, или отключаться совсем.
— Еще одна новая для того времени технология SBR – для чего она была предназначена?
Важное требование для качественного кодирования звука – это достоверная передача широкого частотного диапазона. Однако для традиционного аудиокодера передача каждой следующей октавы звукового диапазона в полтора-два раза повышает требования к битрейту, о чем многие не задумываются. Чтобы снизить битрейт и при этом сохранить верхние частоты в кодируемом материале, была создана технология искусственного синтеза верхних частот SBR (spectral band replication).
Технология основывается на том, что наш слух анализирует верхние частоты с меньшей точностью, чем средние и нижние. Поэтому для создания эффекта присутствия верхних частот необязательно математически точно реконструировать форму волны, а достаточно лишь восстановить некоторые существенные психоакустические параметры сигнала на верхних частотах.
— Существенные – то есть не все? А какие?
К таким параметрам относятся, во-первых, частотно-временное распределение энергии сигнала, то есть попросту его огибающая, а во-вторых, степень его тональности либо зашумленности.
Идея алгоритма такова. При кодировании осуществляется анализ верхних частот в исходном аудиосигнале и извлекаются их параметры. В первую очередь это амплитудная огибающая в нескольких (обычно в восьми) частотных полосах. Далее верхние частоты из записи удаляются и кодируются только оставшиеся нижние и средние частоты. При этом в выходной файл также добавляется сравнительно небольшой поток информации о параметрах утерянных верхних частот.
При воспроизведении сначала декодируется сигнал нижних и средних частот. Далее (в случае его наличия в плеере) начинает работу декодер SBR. Первым шагом он осуществляет синтез высокочастотного сигнала путем частотного сдвига имеющихся средних частот. Поскольку степень тональности/зашумленности спектра на средних и верхних частотах примерно равна, то в результате этого шага получается высокочастотный сигнал с правдоподобной структурой спектра. На втором шаге декодер SBR использует дополнительную сохраненную информацию о верхних частотах для придания им нужной амплитудной огибающей в каждой частотной полосе. В результате получается сигнал, у которого верхние частоты полностью синтезированы из средних, но при этом сохраняют звучание исходных верхних частот!
— Никогда специально не прислушивался к звучанию верхних частот в файлах ААС, но если все так и есть, то это круто!
Да, и при этом технология SBR может быть применена ко многим существующим методам кодирования аудио. Например, SBR в сочетании с МР3 называется МР3 PRO, а SBR в сочетании с AAC называется HE-AAC (high efficiency AAC). В основном, SBR используется при кодировании с относительно низкими битрейтами: 64 кбит/с и ниже. Технология позволяет значительно расширить частотный диапазон аудиосигнала с минимальным увеличением битрейта (несколько кбит/с).
— Другое дело, насколько сейчас, в эпоху широкополосного интернета, актуальна низкопотоковая передача…
Сегодня широкополосный, а завтра мало ли что… А технология уже имеется. Есть и еще один важный момент. Передача стереосигнала обычно требует от кодера почти в 2 раза большего битрейта, чем передача монофонического сигнала. При этом стереоканалы можно кодировать как независимо, так и после M/S преобразования. В последнем случае на S-канал зачастую тратится меньший битрейт, чем на M-канал. Этот режим кодирования называется joint stereo. В стандарте AAC он может включаться и отключаться кодером для каждой частотной полосы.
Для более эффективного кодирования стереосигналов на совсем низких битрейтах (16–32 кбит/с) была разработана технология параметрического кодирования стереопанорамы (Parametric Stereo). Она заключается в том, что стереосигнал перед кодированием сводится к моно, но в выходной файл добавляется небольшой поток (2–3 кбит/с), содержащий информацию о стереопанораме исходного стереофайла. Этот поток содержит (в сжатом виде) своеобразную «карту панорамы» для частотно-временной плоскости.
На стадии декодирования к полученному монофоническому сигналу применяется так называемое частотно-зависимое панорамирование. Это можно производить одновременно с декодированием, применяя к изначально равным коэффициентам MDCT левого и правого каналов соответствующие амплитудные множители.
Технология Parametric stereo дает хорошее впечатление об исходной стереопанораме звука ценой лишь небольшого увеличения битрейта по сравнению с кодированием моносигнала. Однако, надо сказать прямо, она не позволяет добиться полностью прозрачного звучания, так как неспособна учесть все нюансы стереопанорамы, например фазовые сдвиги между стереоканалами.
Технология Parametric stereo была включена в стандарт HE-AAC v2.
— Но это, опять же, решения для совсем проблемного интернета с очень низким потоком, хотя будущее непредсказуемо. А что такое технология PNS?
Это генерация шумов, или синтез шумов. Для дополнительного увеличения эффективности кодирования шумовых сигналов в стандарте AAC предусмотрена технология Perceptual Noise Substitution. Известно, что наше ухо более чувствительно к амплитудному спектру сигнала, чем к фазовому. Поэтому вместо кодирования MDCT-коэффициентов исходного сигнала в шумовых областях можно лишь передавать параметры шума: его мощность в зависимости от частоты и времени.
Так и работает технология PNS. При кодировании идентифицируются участки спектра, представляющие собой шум, и соответствующие группы MDCT-коэффициентов не кодируются. Частотная полоса помечается как шумовая, и для нее запоминается общая энергия шума.
При декодировании в частотные полосы, помеченные как шумовые, подставляются псевдослучайные MDCT-коэффициенты с требуемой общей мощностью. В результате в указанных частотных диапазонах синтезируется шум, близкий по звучанию к исходному шуму.
— Какие еще «тонкости и хитрости» используются в этом формате?
Технология Long-term prediction – предсказание по времени. Психоакустическое кодирование тональных сигналов требует более высокого локального отношения сигнал/шум, чем кодирование шумовых сигналов (например, 20 дБ и 6 дБ соответственно). А это, в свою очередь, требует повышенного битрейта. Однако MDCT-коэффициенты тональных сигналов являются предсказуемыми по времени. Это позволяет использовать их зависимость по времени для уменьшения битрейта.
В стандарте AAC предусмотрен режим Long-term prediction, в котором MDCT-коэффициенты дополнительно кодируются по времени с помощью линейного предсказания. Термин здесь “long-term” означает, что предсказание осуществляется не по соседним отсчетам, а по отсчетам, отстоящим на наиболее вероятный период тона на данной частоте.
— Но все же самое главное – это качество звучания. Что показывают тесты?
При оценке качества звучания аудиокодеров обычно используются субъективные тесты. Слушателям представляются фрагменты сжатых разными кодерами записей, и они оценивают чистоту звучания каждого фрагмента по шкале от 1 до 5. Лучшим кодеком считается тот, который способен достичь более высокого качества звучания по сравнению с конкурентами при заданном битрейте. Поскольку тестирования проводятся регулярно на разных ресурсах разными исследователями, в разных условиях и для разных кодеков, приводить их результаты здесь нет смысла, желающие могут легко найти их в сети.
— Какие же выводы?
Благодаря примененным в стандарте AAC новым технологиям, данный формат имеет заметное преимущество перед MPEG-1 Layer 3 (MP3), позволяя достигать лучшего качества звука при таких же битрейтах. Особенно сильный выигрыш наблюдается в области низких битрейтов: 96 кбит/с и ниже. Это подтверждает перспективность формата AAC для цифрового радиовещания и сетевого стриминга.
Формат AAC не является единственным наиболее качественным форматом компрессии звука. Более новый формат с чуть более высоким качеством называется Opus. Его большое преимущество – бесплатность использования для производителей оборудования и кодеков, в то время как стандарты MP3 и AAC защищены патентами и требуют лицензионных отчислений (недавно срок действия патентов на MP3 истек).
— В конце беседы надо подчеркнуть, что речь шла о так называемом «сжатии с потерями» и сравнении их результатов. Что касается форматов «сжатия без потерь», среди которых наиболее популярны FLAC и ALAC, то это тема для отдельного разговора. Спасибо, Алексей, за полезную, подробную и познавательную информацию!
Привет читателям журнала «Звукорежиссер» и пожелания успехов в работе!